728x90
반응형
Segmentation 모델을 훈련하기 위해 훈련 코드는 복붙, 수정하고 Dataset 클래스는 직접 만들었다.
그랬더니 아래와 같은 오류가 발생했다.
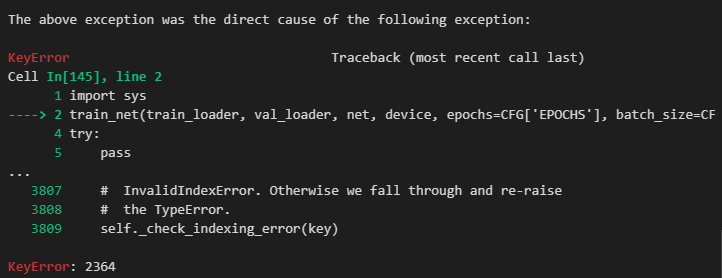
처음에는 복붙, 수정하면서 파라미터가 꼬인 줄 알았지만, pandas의 인덱싱 에러다.
하필 0번째 인덱스를 확인했을 때 잘 돌아가서 오류 위치를 찾는 데 더 오래 걸렸다.
15번째 인덱스를 조회하면 다음과 같이 오류가 발생한다.

from sklearn.model_selection import train_test_split
train_df,val_df,_,__ = train_test_split(train_df,train_df,test_size=0.2,random_state=CFG['SEED'],stratify=train_df.cls)
train_dataset = DAGM(train_df,None)
val_dataset = DAGM(val_df,None)
train_loader = DataLoader(train_dataset,CFG['BATCH_SIZE'],shuffle=True)
val_loader = DataLoader(val_dataset,CFG['BATCH_SIZE'],shuffle=False)
이유는 위 코드에서 DataFrame을 split 해서 DataFrame의 인덱스가 나눠졌기 때문이다.
해결 방법
def __getitem__(self,idx):
return self._to_tensor(self.data.data[idx]), self._get_label(self.data.label[idx])
아래 코드처럼 iloc을 사용하면 된다.
def __getitem__(self,idx):
return self._to_tensor(self.data.data.iloc[idx]), self._get_label(self.data.label.iloc[idx])
iloc을 사용하지 않으면 DataFrame의 정의된 index를 사용하기 때문이다.
728x90
반응형



댓글