이전에 이미지를 패치로 나누고 프로젝션 연산까지 진행하는 코드를 작성했다.
[ViT] Vision Transformer 구현 -0 Linear Projection of Flattened Pathes
Vision Transformer를 모듈별로 구현하며 궁금한 점을 기록했다. Vision Transformer(ViT)의 데이터(이미지) 처리 프로세스를 ChatGPT에게 물어봤다. 입력 이미지에서 패치 추출: 입력 이미지에서 패치를 추출
yeeca.tistory.com
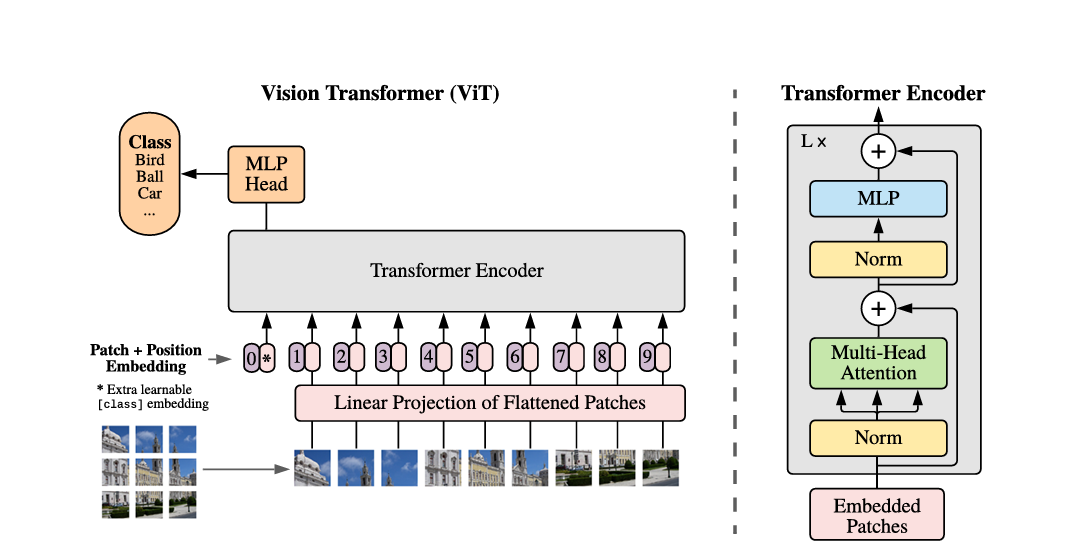
다시 순서를 쓰면 다음과 같다.
1. Patch 추출 및 Embedding
2. Patch + Position Embedding
3. Encoder
4. MLP Head
순서에 따른 결과를 확인하기 위해 임시 이미지 텐서를 만든다. 나중에 Vision Transformer 클래스의 속성 값도 일단 하드코딩한다.
image_size = 224
img = torch.rand((1, 3, image_size, image_size)) # 3채널 컬러 이미지
patch_size = p = 16
embedding_size = 32
projection = nn.Conv2d(img.shape[1], embedding_size, patch_size, patch_size)
1 번을 구현한 코드는 다음과 같다.
def step_1_path_embedding(x):
n,c,h,w = x.shape
n_h = h // p
n_w = w // p
# n,c,h,w -> n,em, n_h*n_w
x = projection(x)
x = x.reshape(n,embedding_size,n_h*n_w)
x = x.transpose(1,2)
return x
re = step_1_path_embedding(img)
re.shape, re
>>>(torch.Size([1, 196, 32]), tensor([[[ 0.1500, 0.0956, -0.8312, ..., -0.5778, -0.3055, 0.0873], [ 0.1251, 0.1126, -0.6352, ..., -0.2666, -0.3322, -0.0958], [ 0.3312, -0.2242, -0.6188, ..., -0.5018, -0.1983, 0.0149], ..., [ 0.0279, 0.1941, -0.6153, ..., -0.7869, 0.0193, 0.1988], [ 0.0771, -0.0667, -0.2745, ..., -0.6418, -0.2404, 0.2012], [ 0.0359, 0.0853, -0.6376, ..., -0.7599, -0.2922, 0.0756]]], grad_fn=<TransposeBackward0>))
x.transpose(1,2) 대신 x.permute(0,2,1)을 실행해도 결과값은 같다. 속도는 어떤 것이 빠를까 궁금해졌다.
img의 batch size를 10,000으로 늘리고 일단 CPU로 연산했을 때를 비교했다.
t = time.time()
re = step_1_path_embedding(img)
print(time.time()-t)
>>>3.1672747135162354
t = time.time()
re2 = step_1_path_embedding2(img)
print(time.time()-t)
>>>2.3926424980163574
다시 비교해도 3.293992519378662, 2.2294838428497314로 permute를 사용하는 것이 더 빠르다.
이번엔 GPU로 비교했다.
t = time.time()
re = step_1_path_embedding(img.to(torch.device('cuda')))
print(time.time()-t)
>>>1.295954704284668
t = time.time()
re2 = step_1_path_embedding2(img.to(torch.device('cuda')))
print(time.time()-t)
>>>1.3160767555236816
t = time.time()
re = step_1_path_embedding(img.to(torch.device('cuda')))
print(time.time()-t)
>>>1.2964231967926025
t = time.time()
re2 = step_1_path_embedding2(img.to(torch.device('cuda')))
print(time.time()-t)
>>>1.2929625511169434
GPU를 사용했을 때는 비슷하다. transpose를 썼을 때 혹은 permute를 썼을 때 모두 속도가 앞설 때가 있었지만 평균적으로 비슷하게 출력된다. 지금은 비슷해 보이지만 복잡한 연산이 섞였을 때 달라질 수 있으니 나중에 다시 확인해야겠다.
위 코드에서 연속으로 돌리면 메모리 초과되므로 free 해줘야 한다.
import gc
del re2
gc.collect()
torch.cuda.empty_cache()
다시 본론으로 돌아가서 patch embedding 의 출력 shape는 (n, n_h*n_w, embedding_size) 이다. embedding_size == hidden_dim
위 shape는 Transformer Encoder의 입력 shape (N, S, E)로 나타낼 수 있다. N은 batch size, S는 sequence length, E는 embedding size이다.
다음은 2 번인 Patch + Position Embedding 의 구현이다.
Position Embedding에 앞서서 Sequence 맨 앞에 Learnable한 Class Token이 부여된다.
# 2. Cat Class Token
# img = torch.rand((2, 3, image_size, image_size))
class_token = nn.Parameter(torch.zeros(1, 1, embedding_size))
class_token.shape
>>>torch.Size([1, 1, 32])
ct = class_token.expand(2,-1,32)
ct.shape
>>>torch.Size([2, 1, 32])
x = step_1_path_embedding(img)
x = torch.cat([ct, x], dim=1)
x.shape
>>>torch.Size([2, 197, 32])
Position Embedding도 마찬가지로 학습 가능한 파라미터이며 Class Token과 달리 add 연산된다.
pos_embedding = nn.Parameter(torch.zeros(1, 197, 32).normal_(std=0.02))
x = x+ pos_embedding
x
>>>tensor([[[-4.0470e-03, 6.4557e-03, 3.2963e-02, ..., 1.4642e-03, 1.5062e-02, 4.9010e-03], [ 2.8400e-01, -1.2977e-01, 4.2060e-01, ..., 1.6136e-02, -7.6180e-01, 2.7562e-01], [-2.7916e-01, 2.5599e-01, 5.9778e-01, ..., -6.7908e-02, -7.0144e-01, 6.7709e-01], ..., [-2.9167e-01, -1.8723e-01, 4.8032e-01, ..., -1.5264e-01, -4.1705e-01, 6.5470e-01], [-8.7477e-02, 7.1068e-02, 2.8797e-01, ..., 2.0111e-01, -8.2252e-01, 4.7584e-01], [ 8.1765e-02, -9.4550e-02, 7.0722e-01, ..., -9.9543e-02, -5.6091e-01, 4.0692e-01]],,,,
여기까지 구현한 Vision Transformer 구현은 다음과 같다.
class VisionTransformer_(nn.Module):
def __init__(self,img_size,patch_size,embedd_dim,):
super().__init__()
self.img_size = img_size
self.p = patch_size
self.embedd_dim = embedd_dim
self.projection = nn.Conv2d(3,embedd_dim,patch_size,patch_size)
self.class_token = nn.Parameter(torch.zeros(1, 1, embedd_dim))
seq_length = (img_size // patch_size) ** 2 +1
self.pos_embedding = nn.Parameter(torch.zeros(1, seq_length, embedd_dim).normal_(std=0.02))
def _patch_embedd(self,x):
n,c,h,w = x.shape
n_h = h // self.p
n_w = w // self.p
# projection
x = self.projection(x)
x = x.reshape(n,self.embedd_dim,n_h*n_w)
x = x.permute(0,2,1)
# concat class token
ct = self.class_token.expand(n,-1,self.embedd_dim)
x = torch.cat([ct,x],dim=1) # (2,197,32)
# add pos
x = x+ self.pos_embedding
return x
def forward(self,x):
# embedding
x = self._patch_embedd(x)
# encoder
# head
return x
vit = VisionTransformer_(224,16,32)
vit(img).shape
>>>torch.Size([2, 197, 32])



댓글